

Le DevFest Nantes 2024 a pris des allures de parc d’attractions hanté, et nous étions aux premières loges pour transformer les visiteurs en créatures de cauchemar ! Après le succès de notre application de dessin augmentée par l’IA en 2023, nous avons relevé un nouveau défi : créer une expérience photo terrifiante mais inoubliable avec l’IA générative. Entre développement surnaturel, tests frissonnants et retours enthousiastes, plongez avec nous dans les coulisses de notre parc d’attractions abandonné, où la technologie a flirté avec l’horreur pour créer notre application PhotoBOOst !
Sommaire
Bienvenue dans votre pire cauchemar…
Imaginez un parc d’attractions abandonné… mais comment le baptiser ? Après de nombreux échanges, nous avons opté pour « Dev-il Park » : un nom qui marie habilement « Dev » pour les développeurs et « Devil » pour l’ambiance démoniaque. Quant à notre attraction développée en interne, elle a reçu le nom « PhotoBOOst » en référence aux « photobooths », les cabines photo dans les lieux publics, au côté « augmenté/boost » insufflé par l’IA et à l’exclamation « boo ! » (« bouh » en français) que l’on utilise lorsque l’on effraie une personne.
Dans notre royaume de l’étrange, cinq types de monstres attendent impatiemment, tapis dans l’ombre, de s’emparer de l’âme des courageux visiteurs : clowns, satyres, loups-garous, vampires et zombies. Leur procédé via PhotoBOOst ? :
- Photo solo ou en groupe, avec des recommandations de notre staff sur les poses, la distance de la caméra et un petit décompte (3, 2, 1) pour la prise de photo effective
- Choix du type de monstre qu’on voudrait être, sans possibilité de mix. Si vous prenez une photo de groupe, tout le groupe incarnera un seul type de monstre.
- Choix entre 2 photos générées
- Photo gauche : très légèrement transformé
- Photo de droite : transformation poussée
- Génération d’une vidéo des monstres en mouvement (course poursuite vers la caméra ou danse endiablée) d’une durée de 5 seconde
Pendant que notre application mijote votre transformation de photo à vidéo avec de l’IA générative, une animation vous plonge dans l’ambiance de Dev-il Park et vous laisse entr’apercevoir les terrifiantes métamorphoses qui s’y produisent. Quelques secondes plus tard, le résultat de votre propre transformation grâce à l’IA s’affiche !
Les rouages techniques de notre attraction PhotoBOOst
Pour donner vie à Dev-il Park, nous avons relevé trois défis majeurs :
- Incruster nos intrépides visiteurs dans un décor de carnaval macabre
- Les métamorphoser en créatures de la nuit
- Les animer pour une expérience immersive
Et nous avons fait appel à un quatuor de technologies redoutables :
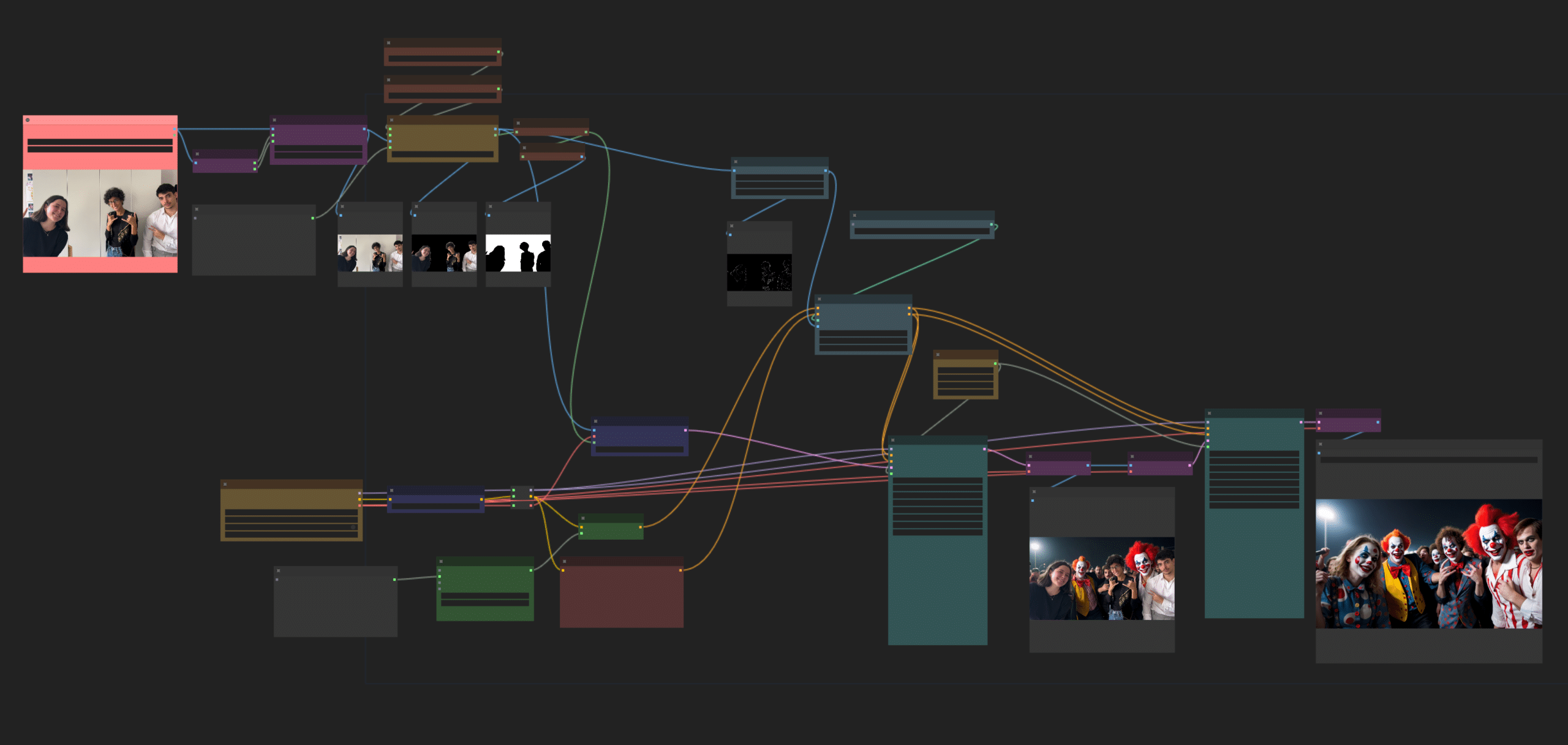
ComfyUI : notre chef d’orchestre
Cette application nous a permis de piloter notre chaîne de production, définir et paramétrer les différentes briques utilisées. Nous y avons créé nos pipelines de générations d’images en raccordant des « nœuds » (= des tâches à exécuter qui ont des entrées, produisent des sorties et ont des paramètres intrinsèques). Cette construction s’est déroulée de manière itérative pour aboutir à une version que nous espérons avoir gardée la plus compréhensible possible.
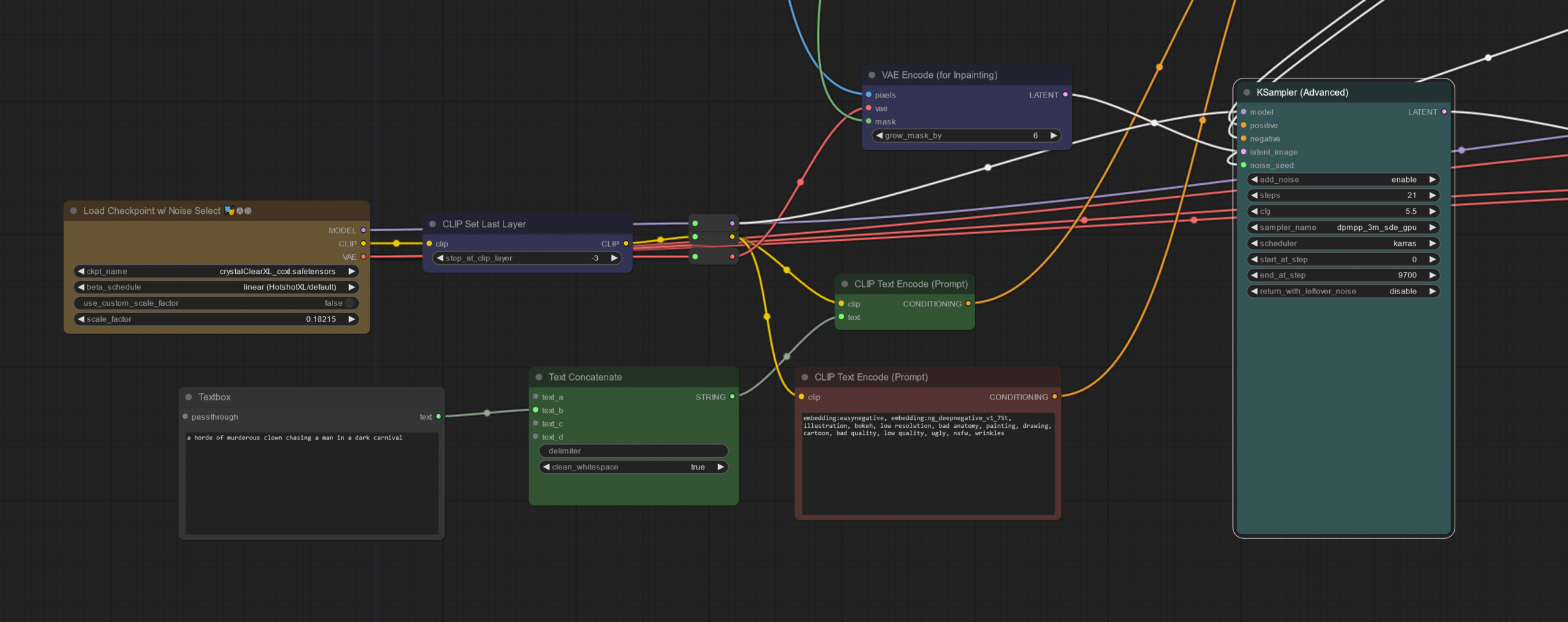
Stable Diffusion : notre artiste polymorphe
Capitalisant sur notre expérience de l’année dernière, nous avons utilisé cette IA pour générer nos backgrounds et transformer nos utilisateurs. Il s’agit d’une famille de modèles d’IA capable de faire de la génération d’images à partir d’un prompt (un bloc de texte en langage naturel). L’année dernière, nous avions utilisé le très populaire mais vieillissant SD1.5 ; cette année, nous avions le choix entre plusieurs modèles :
- SDXL, le successeur de SD1.5 (modèle très populaire)
- SD3, le dernier modèle de Stability.ai
- Flux.dev, le nouveau modèle très prometteur de Black Forest Lab
Après une batterie de tests, notre choix s’est porté sur SDXL, lequel convenait mieux à nos exigences par rapport aux autres. La génération d’images avec SD3 était en effet trop longue pour notre chaîne et les résultats n’étaient pas satisfaisants. Flux.dev, quant à lui, n’était pas compatible avec les « nœuds » choisis.
Une fois le choix du modèle arrêté, quelles sont les étapes pour générer les images des participants dans notre parc d’attractions ?
Notre conception de la chaîne est la suivante : « Générer un background/décor de parc d’attractions en style carnaval de l’horreur en interdisant des zones pour la génération. Puis, transformer uniquement les zones précédemment interdites. » Les zones interdites correspondent à nos participants.
En résumé, nous avons donc un enchaînement de 4 étapes :
- Extraction, pour isoler les participants de leur environnement
- Génération du décor, pour créer notre parc hanté
- Incrustation, pour placer les participants dans le nouveau décor
- Transformation, pour métamorphoser nos visiteurs en monstres
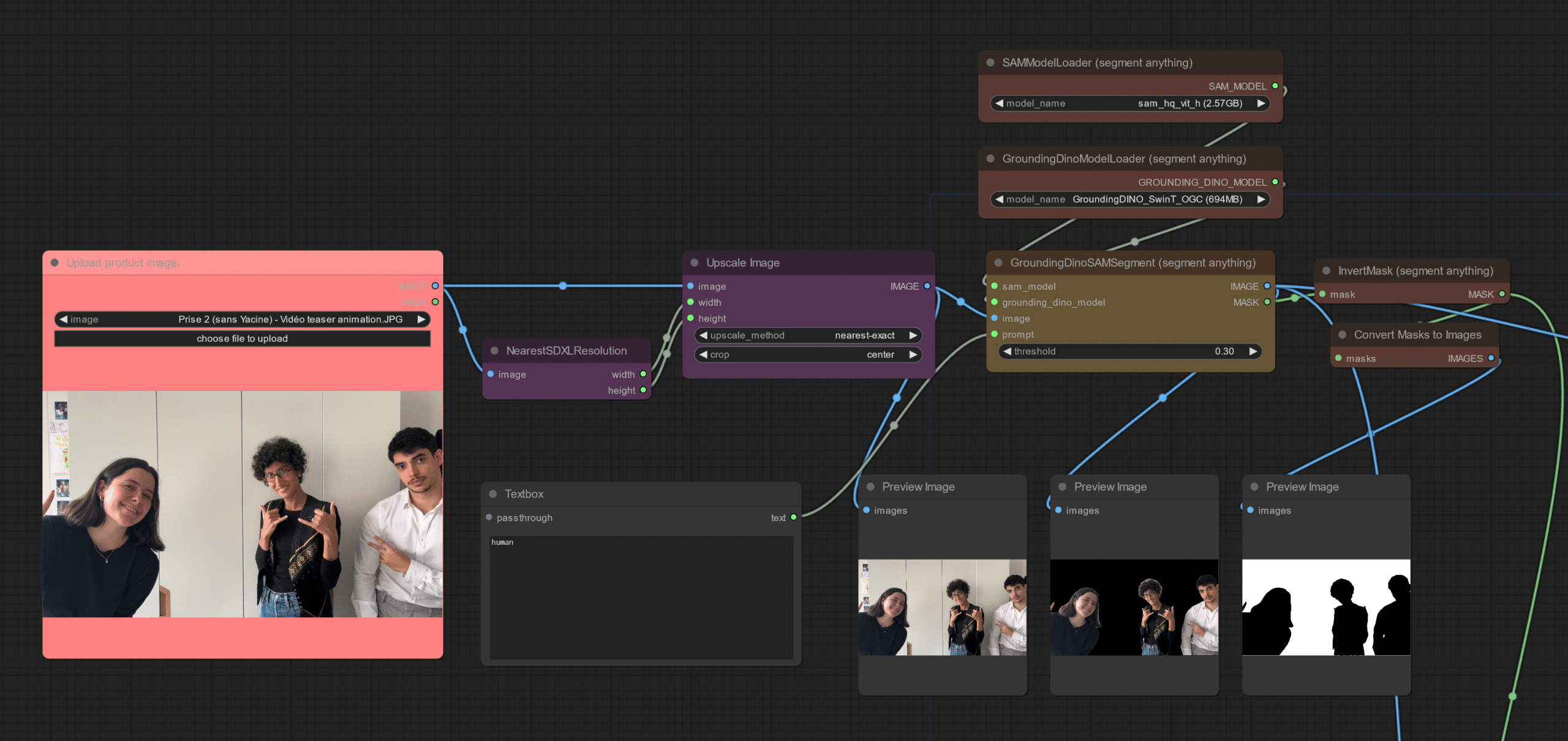
SAM (Segment Anything Model) : notre illusionniste
L’extraction des participants de leur décor original sur notre stand du DevFest s’est faite à l’aide d’un modèle de type SAM (Segment Anything Model), capable de faire de la reconnaissance d’image et dans lequel nous indiquons ce que nous souhaitons « détecter » dans la photo d’origine (ici nos participants). En sortie de ce modèle, nous obtenons un « masque » : une image en noir et blanc qui va déterminer la partie de l’image que SDXL va pouvoir remplacer par un décor de parc d’attractions carnavalesque (en blanc), et la partie qu’il n’a pas le droit de toucher initialement (en noir).
Ci-dessous ce SAM à l’œuvre avec la détection des humains dans la photo d’origine, et la production du fameux « masque ».
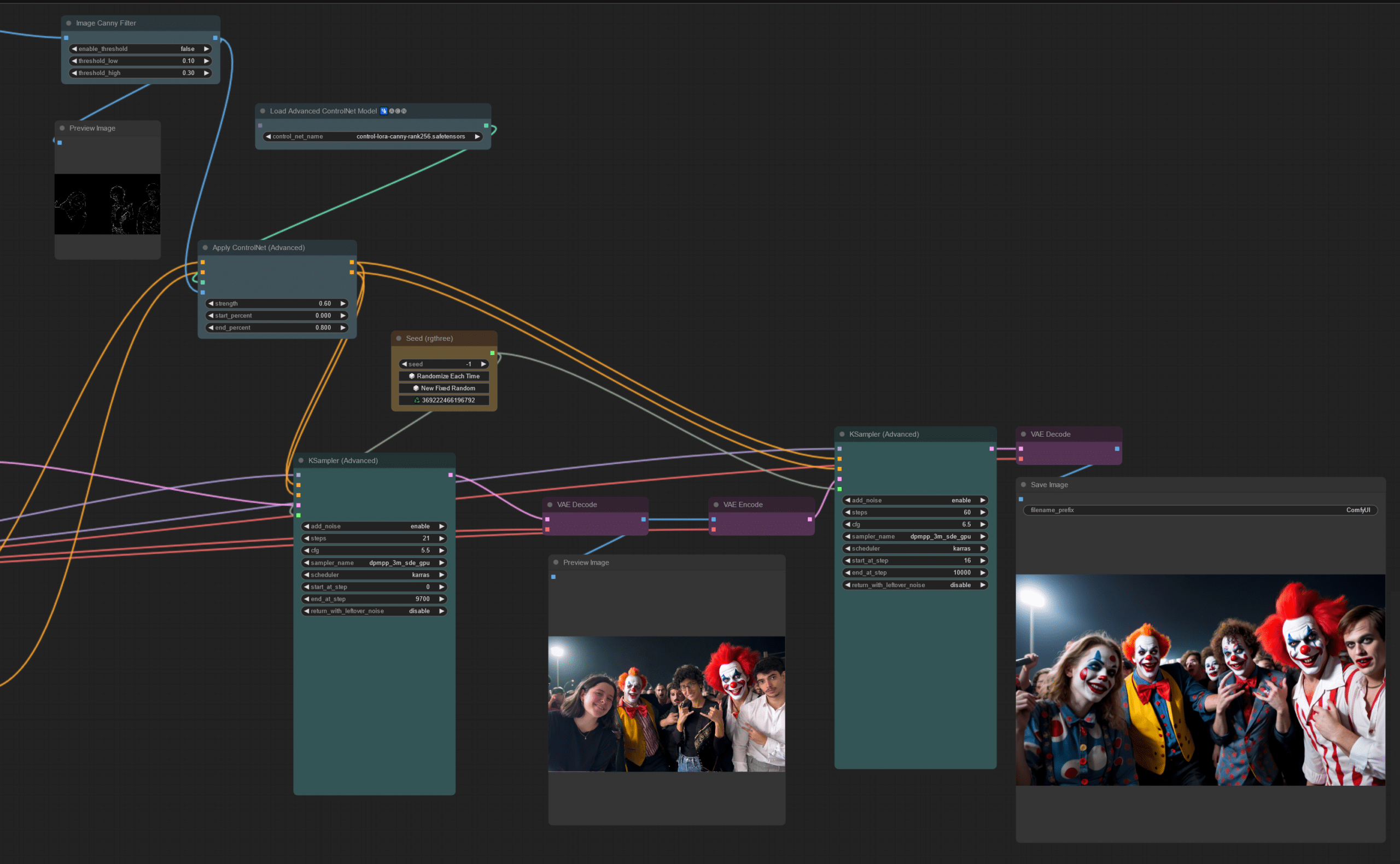
La génération de décor s’est faite de manière habituelle à l’aide d’un prompt.
L’incrustation de nos participants dans le décor généré par IA s’est faite avec l’utilisation de ControlNet : une structure de réseau neuronal permettant d’imposer plus de contrôle sur la génération de l’image. Ainsi, avec le masque et le prompt de génération de décor, une incrustation grossière permet d’avoir a minima nos participants dans un décor généré. Puis, avec le masque et un prompt d’altération des participants, nous avons nos participants « altérés » dans le même décor généré, avec un paramètre d’altération qui nous permet de vous proposer 2 images.
Parce qu’une image vaut bien mille mots :
Luma Dream Machine : notre réalisateur fou
Ce service nous a permis d’insuffler la vie à nos créations statiques et de générer une vidéo à partir de l’image transformée choisie. Il s’agit de l’un des premiers services ayant permis d’animer de manière dynamique une image à partir d’un prompt. Nous avons fait le choix d’utiliser cet outil initialement car il était le seul à générer des vidéos avec un niveau de mouvement/dynamisme satisfaisant pour notre besoin (en contraste à des outils comme Runway ML2 ou AnimateDiff qui ne produisaient que de légers mouvements de caméra et peu de dynamisme dans les mouvements). Lorsque des concurrents sérieux sont apparus (Runway ML3, Kling…), nous avons décidé de rester sur notre choix initial car le temps de génération était devenu très court, ce qui était parfait pour une animation de salon.
Enfin, pour que vous puissiez garder un souvenir de votre passage à Dev-il Park, nous avons réutilisé notre infrastructure de l’année dernière : des lambdas AWS et notre site WordPress pour le visionnage, le téléchargement et le partage de vos créations terrifiantes.
Un lieu abandonné semé d’embûches…
Comme dans toute attraction qui se respecte, nous nous sommes fait quelques frayeurs ! Notre Dev-il Park a connu son lot de défis et de rebondissements en coulisses mais nous avions un seul objectif en tête : vous proposer l’expérience la plus fluide possible.
Avec une équipe partiellement renouvelée, nous avons dû replonger dans les méandres du projet précédent. Répartir les tâches, adapter le processus d’envoi et de partage des médias, et affronter à nouveau les redoutables CORS dans les lambdas AWS : autant de défis qui ont mis à l’épreuve notre résilience et notre créativité.
La génération de vidéos nous a confrontés à deux enjeux majeurs :
- Réduire le temps de traitement pour une expérience fluide
- Garantir une qualité d’animation digne de notre parc hanté
Initialement, la génération d’une vidéo de 5 secondes pouvait prendre jusqu’à 10 minutes (voire plus !), nous obligeant à envisager divers scénarios d’attente. Heureusement, les progrès rapides dans le domaine, en particulier sur l’outil que nous avions sélectionné, ont réduit ce temps à environ 1 minute 30, permettant même aux visiteurs de faire plusieurs essais durant leur session de 5 minutes sur notre stand. Grâce à ces progrès, nous avons également pu profiter d’améliorations sur le contrôle de la génération, afin d’améliorer les mouvements dans nos résultats.
Contrairement à la génération d’images statiques, créer des prompts pour les vidéos s’est révélé être un art à part entière. De manière naïve, nous pourrions croire qu’une vidéo représente une succession d’images clés, qu’il nous suffirait de mettre dans une boîte magique qui s’occuperait de faire le lien entre toutes ces images (à la façon d’un dessin animé par exemple). Que nenni ! La littérature existante nous apprend d’ailleurs déjà qu’à l’heure actuelle une telle méthode ne peut pas garder de cohérence entre les images. Nous avons donc dû adopter une approche « cinématographique » en pensant aux plans et aux mouvements pour passer d’un plan à l’autre, ce qui nous a permis de créer des animations cohérentes et dynamiques, évitant les pièges des simples successions d’images clés.
Par exemple, pour une image, on se concentre sur une description des éléments la composant :
- Le sujet de l’image (personnages + décor)
- Une description détaillée du sujet de l’image (détails sur personnages et décor)
- L’ambiance de l’image, les couleurs à utiliser
- Le style de génération (manga, peinture pointilliste, BD, etc.)
- La composition
Alors que pour une vidéo, on se concentre plutôt sur le mouvement :
- Les sujets de la vidéo avec une gros focus sur les personnages
- Leur position 3D dans le décor
- Leurs actions par rapport au décor (danser, courir, sautiller, etc.)
- Les émotions qu’ils doivent retransmettre (joie, tristesse, peur, etc.)
- Les mouvements de caméra par rapport aux sujets de la vidéo (courir vers la caméra, la caméra tourne autour des danseurs, etc.)
- Des précisions possibles sur les éléments de décor (setting) et leurs mouvements (ex : grande roue dans un carnaval, nuages dans le ciel…)
Concernant la génération de contenus et les choix de prompts, nous avons souhaité qu’ils soient les plus inclusifs, laïcs et éthiques possibles. Ces choix ont ainsi été rudes pour respecter certains critères :
- Être neutres en termes de genre
- Limiter la sexualisation du genre féminin
- Ne pas effacer la diversité culturelle
Notre objectif était d’offrir assez de choix de transformations pour que tout le monde puisse avoir une option qui donnerait un résultat décent. En effet, la génération d’images par IA, n’est pas magique. Pour résumer, les modèles sont entraînés sur une liste conséquente d’images qui constituent un référentiel d’apprentissage. Sur la base de ce référentiel, le modèle se construit une « définition » des sujets des images. Il génère ensuite des images à partir de nos indications (prompt) et de la base d’apprentissage qu’il s’est construit.
Par conséquent, cela entraîne des biais cognitifs : si l’on demande à une IA de dessiner un clown sans lui donner d’infos spécifiques, elle va générer un clown qu’on qualifierait de « générique » : peinture blanche sur le visage, cheveux colorés et frisés et nez rouge, grand sourire joyeux (loin du sourire effrayant du clown dans Ça de Stephen King)… Cette transformation serait donc appliquée aux participants, sans égard pour leurs caractéristiques culturelles. De même, les vampires modernes sont souvent représentés comme étant « sexy » (en particulier les femmes vampires), ce qui peut entraîner des transformations un peu trop « osées » pour certains.
Malgré ces limitations dans les choix des prompts et le temps de l’animation, nous avons réussi choisir des personnages de l’imaginaire connus de tous (même si nous aurions peut-être dû revoir le nom de « satyre » qui a prêté un peu à confusion…), tout en proposant une durée d’expérience raisonnable pour en faire profiter un maximum de personnes !
Deux jours pleins d’émotions : un succès monstrueux !
Nos efforts ont porté leurs fruits, transformant notre stand en véritable attraction du DevFest. Les visiteurs ont été stupéfaits par les prouesses de l’IA générative et le fonctionnement de notre application.
L’un des aspects les plus remarqués a été la préservation des vêtements et accessoires des participants. Malgré le degré de transformation parfois radical par l’IA générative, chacun pouvait se reconnaître sur sa photo grâce à ces détails conservés. Certaines vidéos sont mêmes allées jusqu’à préserver les textes et logos sur les vêtements, démontrant la finesse de notre système. Pour nous, c’était un excellent résultat, surtout dans le cas d’usage très particulier que nous avions imaginé. Vous avez toujours rêvé d’incarner un personnage et d’en faire un court film ? À vous de jouer !
Un petit défaut dans la génération vidéo a ajouté une touche d’humour inattendue. Pour assurer un dynamisme suffisant, nous avons dû forcer certains mouvements, résultant parfois en des déformations dignes du « body horror ». Loin d’être un problème, cela a contribué à l’aspect terrifiant tout en suscitant des rires complices : pari réussi !
En dépit de nos craintes initiales, PhotoBOOst a brillamment relevé le défi des groupes. Que ce soit pour un participant seul ou un groupe de 5-6 personnes, les résultats restaient impressionnants. Le record ? Une photo de 10 personnes transformées en zombies !
La détection et l’incrustation des participants dans notre décor de folie restent un élément notoire de notre application car cela a fonctionné sans accroc pendant les deux jours de DevFest. Pas besoin de fond vert pour chaque photo, notre IA s’est chargée de tout, pour le plus grand plaisir des visiteurs.
Ces deux jours ont été une véritable démonstration des capacités actuelles de l’IA dans le domaine de l’image et de la vidéo. Les participants sont repartis avec des souvenirs uniques et une nouvelle perspective sur les possibilités offertes par ces technologies en constante évolution.
Dev-il Park ferme ses portes, pour le moment…
L’aventure Dev-il Park nous a plongés au cœur de l’évolution fulgurante de l’IA dans le domaine de l’image, photo et vidéo. Chaque jour repousse les limites du possible, ouvrant la voie à des applications commerciales innovantes et à l’émergence de solutions open-source prometteuses. Grâce à ce projet, nous avons exploré les outils disponibles, cerné leurs capacités et leurs limites, et imaginé de nouveaux usages dans divers domaines. Cependant, plusieurs défis restent à relever :
- Amélioration des personnages : réduire les déformations, notamment au niveau des mains, lors des mouvements.
- Cohérence visuelle : maintenir l’apparence des personnages lors des rotations, afin d’éviter les changements inopinés de visage ou de vêtements. L’une des astuces données par quelques sites est par exemple d’éviter tout mouvement qui peut faire perdre de vue un élément persistant à la caméra.
- Fluidité des mouvements : affiner les animations pour éliminer les aspects saccadés ou synthétiques.
Il est important de noter que notre approche privilégiait l’impact émotionnel et la démonstration des capacités de l’IA avec des prompts simples. Pour un projet plus ambitieux, comme la production d’un film complet, une stratégie différente serait nécessaire, impliquant des prompts ultraprécis ou la génération de multiples scènes suivie d’un montage minutieux.
Finalement, Dev-il Park a démontré aux participants du DevFest que la création vidéo n’est plus réservée aux professionnels. Désormais, chacun peut donner vie à ses idées les plus folles, avec pour seules limites son imagination et sa volonté d’apprendre. Nous espérons avoir inspiré nos visiteurs à explorer ces nouvelles possibilités et, peut-être, à inventer les usages de demain ! Alors que les portes de notre parc d’attractions abandonné se referment, nous sommes déjà impatients de vous surprendre lors de la prochaine saison. Qui sait avec quelles nouvelles merveilles technologiques nous allons nous amuser ? Rendez-vous au DevFest Nantes 2025 pour le découvrir !


