

Le DevFest Nantes 2023 : on a adoré y participer et échanger avec vous autour de l’IA !
Pour l’occasion, on a développé une application de dessin avec de l’IA générative. Vous avez été nombreux et nombreuses à nous demander : comment avez-vous développé cette superbe animation ? Combien de temps y avez-vous passé ? Qu’avez-vous utilisé comme technologies ?
Comme le partage d’expertise c’est dans notre ADN, on a tenu à attiser votre curiosité via une petite épopée en 6 épisodes pour vous replonger dans notre saga Da(rk)veo “Le cloud contre-attaque”.
SPOILER ALERT : Vous risquez de devenir un artiste de renom grâce à la technologie !
Sommaire
- Épisode 1 : Une nouvelle inspiration
- Épisode 2 : Les difficultés contre-attaquent
- Épisode 3 : Le retour du REX
- Épisode 4 : La revanche sur site
- Épisode 5 : La menace des années à venir
- Épisode 6 : La checklist des clones
Épisode 1 : Une nouvelle inspiration

Après des brainstormings intenses, des recherches à gogo et des discussions enflammées, nous, jeunes padawans de l’IA, avons trouvé nos maîtres Jedi pour nous inspirer et nous donner le courage de nous engager et d’entrainer nos forces.
Ces maîtres avaient partagé sous forme de vidéos des générations d’images en temps réel à partir de dessins qu’ils étaient en train de réaliser. Plutôt sympa, non ?
Et nous voilà partis pour vous embarquer dans notre magnifique programme de Dessin en temps réel dans notre univers de Star Wars Lego (not only) !
Tous azimuts, nous nous sommes lancés dans nos premières expérimentations. Pour ce faire, nous devions déjà maîtriser le vocabulaire et identifier les éléments nécessaires pour faire de l’IA générative :

- Prompt : phrase ou court paragraphe qui sert de commande écrite pour une IA chargée de générer du contenu ; cela constitue le cadre de l’IA. Ex : “un singe mangeant une banane”. Ces commandes se trouvent plus généralement en anglais.
- Latent diffusion models (ou LDM) : modèles itératifs qui prennent en entrée du bruit conditionné avec un texte ou une image. Ils apprennent itérativement à supprimer ce bruit en mémorisant quels paramètres le modèle doit appliquer à ce bruit pour aboutir à une image finale. Ils accèdent à des images réelles avec lesquelles ils ont été entraînés pendant leur formation (autrement connu sous le terme de machine learning).
Nos premiers essais se sont basés sur des transformations de type “text-to-image”, qui sont celles relayées le plus dans les différents médias, en utilisant des prompts et des outils de génération d’images par IA : Stable Diffusion, DALL-E, Midjourney et consorts.
Quelques exemples ci-dessous où nos apprentissages concernaient :
- Rendu d’environnement
- Rendu de personnages au format Lego
- Combinaisons des rendus
- Intégration de notre logo Daveo sur chaque image générée









Nos essais suivants se sont portés sur les éléments nous permettant de nous rapprocher des vidéos de nos maîtres Jedi dont l’objectif était de transformer un croquis en une image stylée.
Quelques exemples ci-dessous en utilisant les fonctionnalités des générateurs d’images avec des modèles de Lego et nos réflexions d’interface :



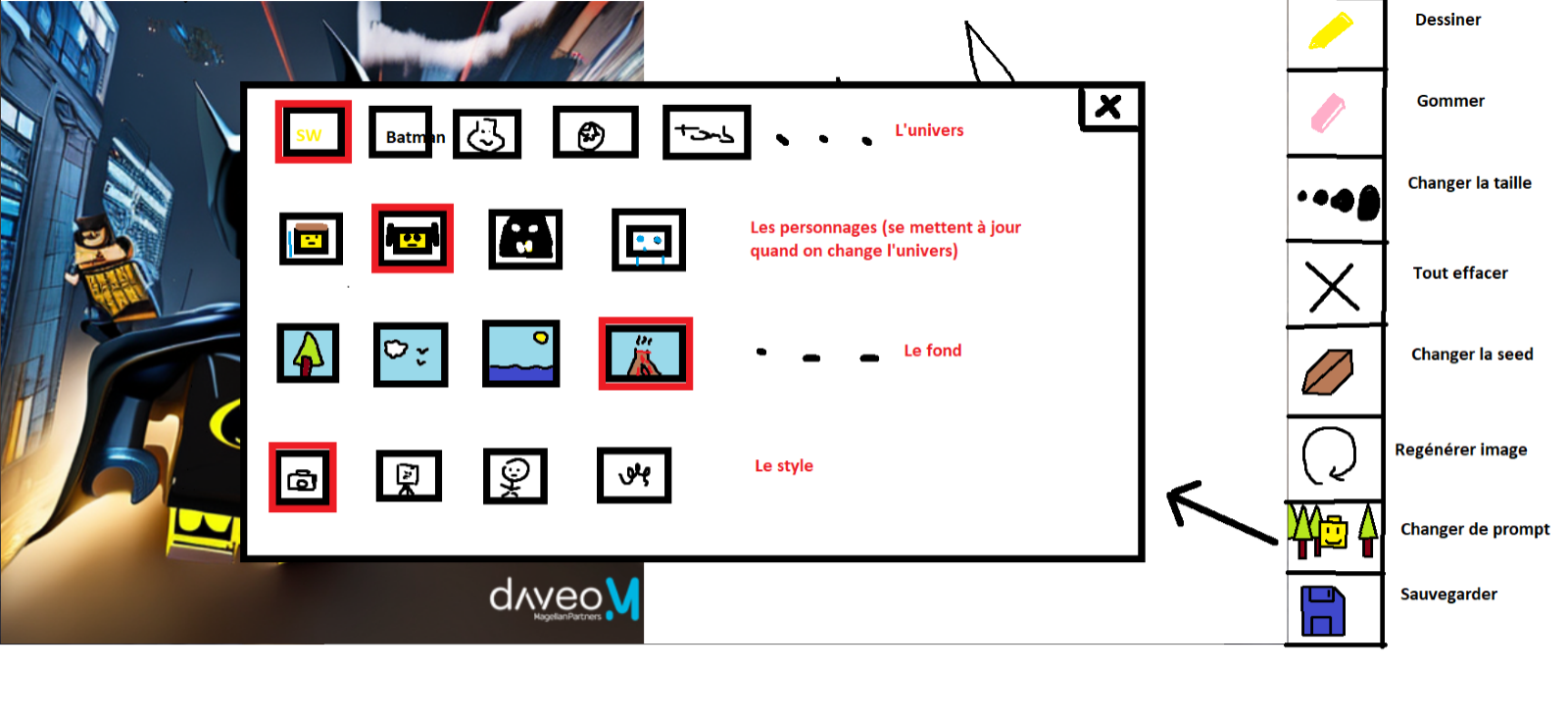
Tous ces essais pour aboutir le jour J au scénario suivant :
- Scène 1 : Scan de votre QR Code pour participer au jeu concours
- Scène 2 : Choix d’un prompt parmi les 6 proposés
- Captain America, cité urbaine avec un terrain gazonné
- Batman, cité urbaine
- Maître Yoda, forêt
- Dark Vador, volcan
- Wonder Woman, cité grecque antique
- Catwoman, cité urbaine
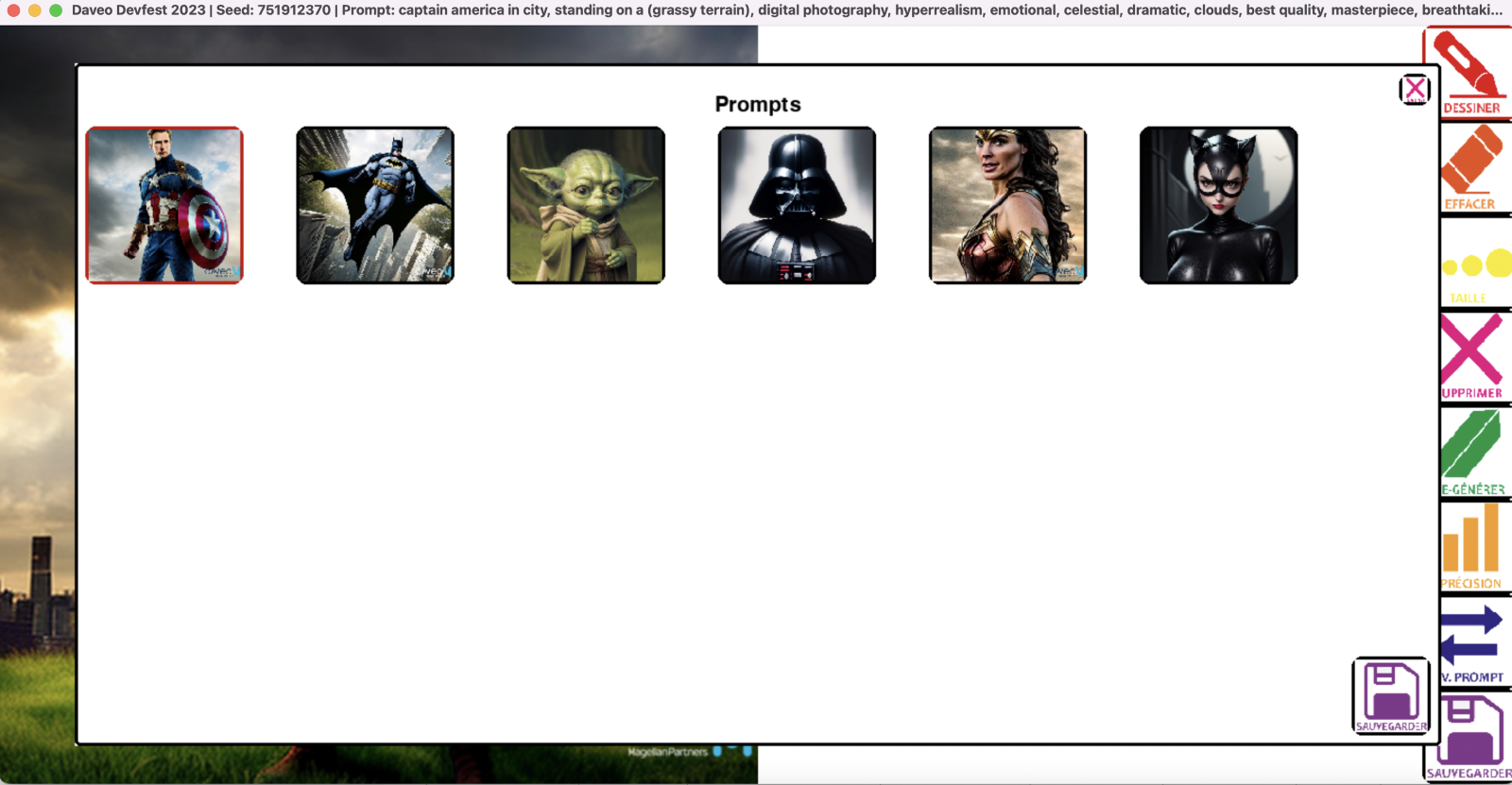
Suite à la confirmation, génération d’une image aléatoire à partir du prompt :

- Scène 3 : Votre dessin avec mise à jour de l’image générée en temps réel (PROMPT + LDM + Code applicatif)
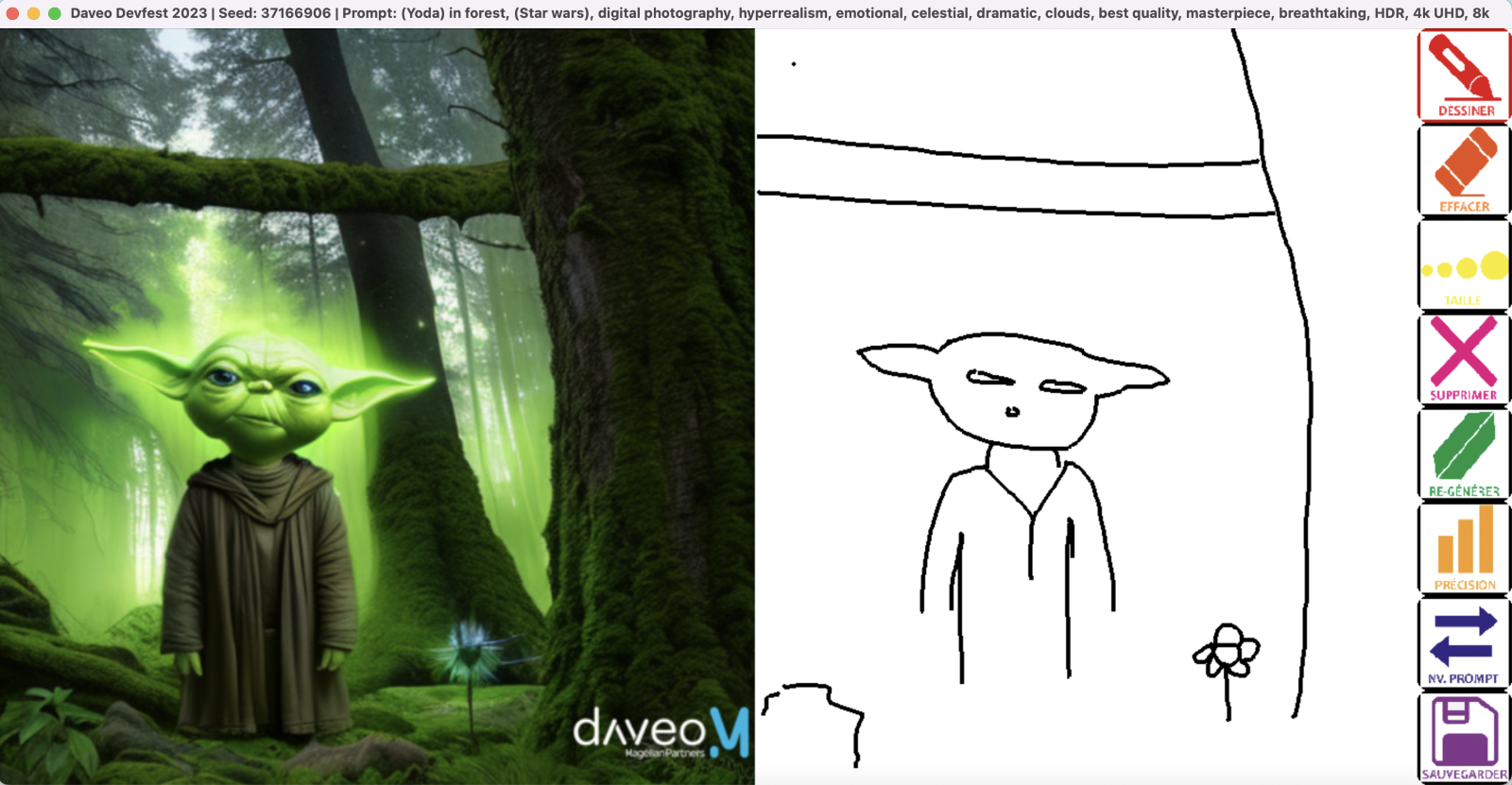
Répétez les scènes 2 et 3 autant que vous le désirez.
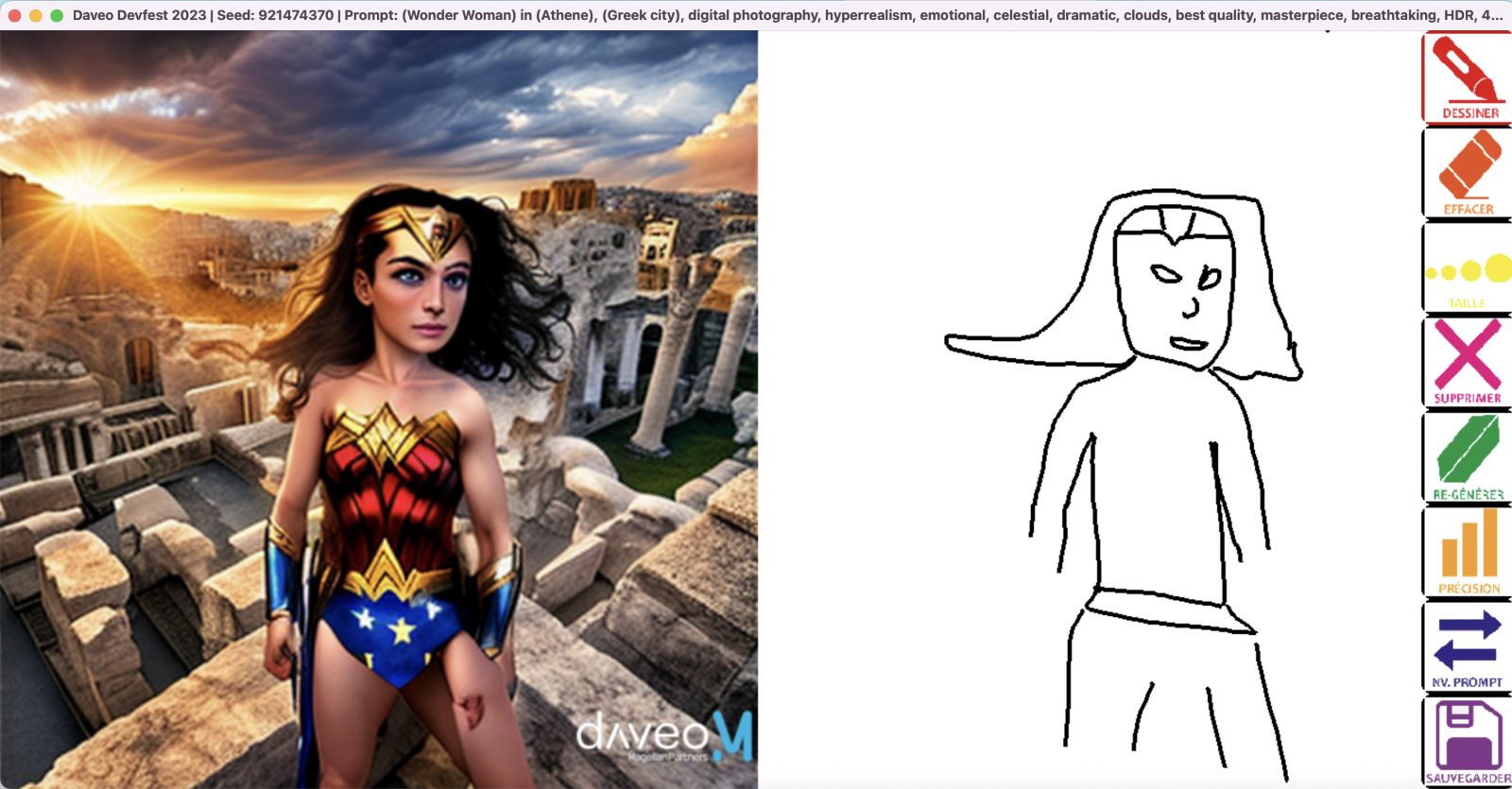
- Scène 4 : Transformation de l’image générée en Lego pour publication sur notre site web (image de la scène 3 + PROMPT + transformation Image-to-Image)

- Scène 5 : Génération d’un QR Code avec lien de l’image pour la partager et accumuler plein de votes pour tenter de remporter le lot R2D2 en Lego
Suivez notre parcours d’apprentissages de jeunes apprentis Jedi dans les méandres de nos expérimentations !
Épisode 2 : Les difficultés contre-attaquent

Une fois l’inspiration trouvée, première mission lancée : faire un POC (Proof Of Concept) avec comme objectif… aller dans l’espace ! Enfin non, plus sérieusement, définir la stack technique de notre application pour vous embarquer dans notre univers, en obéissant aux contraintes suivantes :
- ne pas dépendre uniquement d’une connexion Internet
- respecter un budget limité
- générer des images avec des personnages en Lego
- ne pas proposer de modification de prompts pour éviter des contenus NSFW (Not Safe For Work)
- avoir une bonne qualité d’images générées
- réduire le temps de génération d’images
- proposer une expérience utilisateur agréable pour le dessin notamment
Étape 1 : Choisir l’IA génératrice d’images
Notre choix s’est porté sur Stable Diffusion, une IA facile à prendre en main dans sa version on-premise et gratuite !
Et en bonus, la majeure partie du projet est en open source ! Nous avons notamment décidé d’utiliser le projet GitHub – AUTOMATIC1111/stable-diffusion-webui: Stable Diffusion web UI comme base.
Étape 2 : Résoudre un problème de qualité des images
C’est bien beau de générer des œuvres d’arts mais, si nous n’arrivons pas à obtenir une esthétique Lego, tout est perdu. Heureusement nous n’étions pas seuls. Toute une communauté libre et rebelle travaille d’arrache-pied pour fournir toujours plus de modèles afin d’agrandir l’horizon du possible. Un passage sur les nombreuses bibliothèques en ligne (comme https://huggingface.co/) nous suffit à trouver l’élément qui nous manque : un modèle de génération d’image entraîné pour faire des images avec des personnages Lego.
Étape 3 : Intégrer la prise en compte d’un dessin

Il nous fallait pouvoir faire en sorte que l’IA interprète ce que dessine l’utilisateur, et en tienne compte lors de ses générations d’images. Pour ce faire, il existe un projet / plugin nommé ControlNet. Pour faire simple, il s’agit d’un réseau de neurones qu’on peut brancher sur Stable Diffusion afin d’avoir plus de contrôle sur celui-ci.
C’est un outil vraiment incroyable, capable d’”injecter” des dessins dans la génération d’images. On obtient alors une nouvelle image où les formes correspondent à celles que l’on a dessinées (cf image ci-dessus).
Nous avons utilisé le plugin GitHub – Mikubill/sd-webui-controlnet: WebUI extension for ControlNet conçu pour Stable Diffusion WebUI afin d’ajouter ControlNet à notre POC.
Étape 4 : Créer des prompts solides
Nous voici alors avec une IA capable de nous faire traverser les étoiles ! Cependant, un élément essentiel manque à l’appel : les prompts.
Tout comme un droïde, Stable Diffusion a besoin qu’on lui explique en détail notre plan pour qu’il puisse marcher correctement. L’IA, contrairement aux Jedi, n’est pas magique : il faut lui détailler ce que l’on souhaite créer comme images afin de le guider, et ce, tout en restant concis…
Comme l’a si bien dit maître Yoda, la peur est le chemin vers le Côté Obscur. Pour vous rassurer, il existe beaucoup de ressources en ligne pour vous aider à faire cette tâche ardue, comme par exemple https://stable-diffusion-art.com/prompt-guide/
Décortiquons ensemble un prompt pour comprendre comment les construire :

- On commence avec le sujet : une description de ce qu’on souhaite avoir dans l’image. Chaque mot compte, et plus un détail est loin dans le prompt, moins il aura d’impact dans le résultat final !
- Ensuite, on ajoute un medium. Cette partie va impacter le design global de l’image : “Oil painting”, “Pencil drawing”… Les choix sont infinis !
- Un point important à ne pas négliger : le style. Il faut expliquer à l’IA la composition de l’image qu’on souhaite générer, afin de l’aiguiller dans la bonne direction.
- Pour ce prompt, le design du ciel n’est pas une priorité. On peut donc se permettre de donner une suggestion relativement loin dans le prompt, afin de pousser l’IA dans une direction mais sans trop la forcer.
- Enfin, on termine avec une série de mots-clés pour aider à améliorer la résolution, afin de pousser l’IA à générer des images plus détaillées.
Il s’agit là bien évidemment d’un exemple. Contrairement à ce que vous diraient les Sith, il n’existe pas de manière parfaite de construire ces prompts. Pour devenir un maître Jedi de l’IA, il faut essayer, encore et encore, et modifier légèrement le prompt jusqu’à obtenir des résultats qui vous plaisent.
Étape 5 : Créer une interface de dessin
Maintenant que l’on a réuni tous ces éléments, notre animation est presque prête… À un détail près : l’utilisateur doit avoir à disposition une interface pour dessiner et voir le résultat de son travail ! Pour ça, nous avons créé une petite interface en python via PyGame, qui envoie périodiquement le dessin de l’utilisateur à Stable Diffusion et affiche l’image générée lorsqu’elle est prête.
Étape 6 : Réduire le temps de génération des images
Cependant, il reste un problème majeur qui n’aura pas échappé à certains d’entre vous : générer des images, c’est long ! La génération d’image est une tâche qui met la plupart des GPU à genoux, même les plus modernes. Alors générer des images en temps réel, ce n’est pas gagné !
Etant donné que nous ne pouvions pas demander à nos utilisateurs d’avoir la patience d’Obi-Wan, il nous a fallu trouver des solutions alternatives :
- Dans un premier temps, pas possible de l’éviter, on a dû upgrader notre PC. Avec une Nvidia RTX 4070, on se retrouve alors avec des performances plus que correctes et des images générées dans un temps acceptable.
- Ensuite, nous avons joué avec le nombre de passes lors de la génération d’image. Pour générer une image, l’IA commence par générer une image qui ressemble à un nuage de pixels de toutes les couleurs. Puis, itérativement, il va améliorer cette image jusqu’à obtenir l’image finale. Chacune de ces itérations, de ces “passes” prend du temps mais améliore la qualité de l’image finale. Nous avons fait le choix de limiter ce nombre de passe afin d’accélérer la génération.
Épisode 3 : Le retour du REX

La réalisation de cette animation a été l’occasion pour la plupart de l’équipe de dev de rentrer dans le monde de l’IA et de la génération d’image. De ce fait, nous avons fait beaucoup d’expérimentations, de découvertes et d’allers-retours. Notre team était constituée d’entre 3 à 5 développeurs, qui ont travaillé de mars à octobre.
Quelques limitations à l’horizon
Notre application a quelques limitations. Il est très dur de transformer en détail un dessin : le modèle utilisé est un modèle dit scribble (“gribouiller” en français). Ce modèle va utiliser les traits et les reproduire sur l’image. Plusieurs traits très proches ont tendance à être considérés comme un même trait, mais plus gros. Lors de nos premiers tests, nous avions remarqué que 2 clans s’étaient formés : ceux qui dessinaient naturellement des bonhommes-bâtons et ceux qui dessinaient les contours des personnages. Il a donc fallu expliquer le modèle choisi et ses limitations.
De même les mains, les visages et les textes ont beaucoup de mal à être générés par les modèles actuels. Les détails ont aussi tendance à être répétés.
Les limitations les plus compliquées restent liées au prompt utilisé : il est compliqué de générer un élément qui est “hors-sujet” et la génération de plusieurs personnages reste compliquée.

Ces limitations nous ont donc obligés à créer des guidelines :

Même si les recommandations ne sont pas suivies, des images sont générées en quelques secondes après ajout de quelques traits. Nous avons passé des heures à dessiner, à jouer, à nous amuser et à faire contribuer nos collègues nantais et parisiens.
Des améliorations en vue
Côté technique, nous préparons des améliorations sur cette belle application afin de la rendre disponible sur tout type de support. Personne n’a envie de se balader avec une tour d’ordinateur de plusieurs kilos pour générer un dessin. Arrivera-t-elle avec de nouvelles fonctionnalités ? Allons-nous générer notre propre modèle ? Verrons-nous d’autres filtres que les Lego ?
Si nous devions refaire cette expérience, nous opterions pour une approche différente :
- Le premier point, qui est probablement le plus important, est la stabilisation du besoin : Quel style d’image souhaite-t-on créer, et existe-t-il des éléments déjà existant (modèles ou autre) pour nous aider à obtenir ce style ? En effet, l’esthétique Lego a été un challenge, que nous avons résolu relativement tard. Avec notre expérience actuelle, nous serions en mesure de rediriger le style vers quelque chose de plus simple pour l’IA, ou de trouver un modèle adapté au besoin.
- Ensuite, un gros axe d’amélioration serait la création de prompts. Forts de l’expérience que nous avons acquise au cours de nos expérimentations, nous sommes capables d’obtenir des prompts plus pertinents de manière plus rapide.
Épisode 4 : La revanche sur site
Nous avons recueilli les impressions des participants tout au long du DevFest. Dans l’ensemble, les réactions étaient enthousiastes et témoignent de l’intérêt suscité par cette nouvelle technologie.
Un véritable plaisir partagé autour de cette activité créative et ludique.
De nombreux participants ont exprimé leur émerveillement face à la manière dont leurs dessins se transformaient en images réalistes et dynamiques grâce aux prompts proposés et modèles que nous avions choisis. Certains ont même qualifié cela de “magique” et ont été impressionnés par la qualité des résultats obtenus. Un participant a même déclaré : “C’est incroyable de voir comment un simple dessin peut être transformé en une image aussi détaillée et fidèle au dessin en quelques secondes.”
D’ailleurs, certaines fonctionnalités disponibles n’ont pas été utilisées pour obtenir ces résultats. A nous de réfléchir à quoi en faire pour les prochaines versions.
Ils appréciaient de pouvoir voir instantanément le rendu final de leurs talents artistiques et étaient fiers de partager leurs créations avec leurs collègues et amis.
Certains participants ont également souligné l’aspect pédagogique de cette animation. Ils ont trouvé intéressant d’observer le processus de transformation de leurs dessins en temps réel, ce qui leur permettait de comprendre un peu mieux les mécanismes sous-jacents de cette technologie et du potentiel que cela pouvait avoir.

Enfin, quelques participants se sont montrés curieux du fonctionnement interne de cette technologie et ont exprimé leur désir d’en savoir plus. Certains ont même sollicité des informations sur les algorithmes et techniques utilisés pour réaliser cette génération d’images en temps réel.
En résumé, les réactions des participants étaient extrêmement positives. Ils ont été enchantés par cette animation unique et originale, et ont apprécié l’opportunité de participer à une expérience à la fois divertissante et éducative.
Épisode 5 : La menace des années à venir
Les outils de génération d’image via des IAs évoluent de plus en plus. StableDiffusion, que nous avons utilisé via son modèle en version 1.5, a vu, après les versions 2.0 et 2.1, la version SDXL 1.0 se lancer le 18 juillet 2023. Cette version propose une meilleure qualité de génération d’image au prix d’une consommation en ressources plus élevée. De nombreux modèles et de nombreux plugins sont en développement pour utiliser cette version. Enfin, un modèle en version 1.6 vient de sortir et Stability.ai a désactivé ses APIs en 1.5 le 15 novembre 2023.

Du côté de Dall-E, OpenAI sort sa version 3 cet automne. Cette version propose des images plus détaillées et est disponible pour le moment via les abonnements ChatGPT Plus et Entreprise. MidJourney a sorti son modèle en version 5.2 le 22 juin 2023. Enfin, des applications de l’IA générative sont disponibles dans d’autres applications, comme par exemple avec Photoshop qui permet maintenant de modifier une image directement via un prompt.
De nombreux autres concurrents, comme Bria, Wombo.ai, Craiyon, …
Les applications de la génération d’image sont infinies et il nous tarde de voir ce que le futur nous réserve.
Entre nos retours d’expérience, le potentiel remonté par les participants ainsi que les opportunités offertes par les évolutions sus-citées, notre première brique se monte par un projet interne dont les fonctionnalités seront de rendre l’application disponible partout, sans avoir à déplacer une machine surpuissante et utiliser StableDiffusion dans le cloud, pour un déploiement facile et automatisé.
Épisode 6 : La checklist des clones

Maintenant que vous nous avez suivi dans nos différentes péripéties de cette formidable aventure, quel semble être le modus operandi pour réaliser une application de dessin à base d’IA générative avec succès ?
- Etablir vos critères d’importance pour la génération d’image : performance, modèles disponibles, coûts, rédaction et interprétation des prompts, etc.
- Déterminer l’IA générative d’images selon les critères établis dans l’étape précédente
- Regarder comment fonctionne la techno choisie (dall e/midjourney/stable diffusion/autre)
- Trouver les modèles ou Construire son modèle, selon son niveau d’expertise et son besoin
- Mettre en place la stack technique choisie
- Mettre à disposition rapidement une version auprès d’un public divers pour récolter le plus de feedback possible
- Se rappeler que “la force est en nous !”


