Simple Storage Service
S3 est une plateforme de stockage globale accessible depuis n’importe quel endroit disposant d’une connexion Internet. Il s’agit d’un service AWS public qui fonctionne à partir de toutes les régions AWS, ce qui en fait une ressource disponible dans le monde entier. Cependant, S3 est basé sur des régions, ce qui signifie que vos données sont stockées dans une région AWS spécifique et qu’elles ne quittent jamais cette région, à moins que vous ne le configuriez explicitement.
La résilience régionale garantit que vos données sont répliquées à travers les zones de disponibilité de cette région, ce qui les rend tolérantes à la défaillance d’une zone de disponibilité (AZ) et offre une durabilité de 99,999999999 % (11 neuf). En outre, S3 a la capacité de répliquer les données entre les régions, offrant ainsi une couche de protection supplémentaire pour vos données.
Si S3 peut sembler déroutant au premier abord, il est facile à utiliser une fois que l’on a compris sa structure régionale. Lorsque vous utilisez S3 à partir de la console AWS, vous n’avez pas besoin de sélectionner une région. Au contraire, vous sélectionnez une région lorsque vous créez des ressources dans S3. Il est ainsi facile de gérer vos données et de vous assurer qu’elles sont stockées dans la bonne région.
S3 est conçu pour gérer des quantités illimitées de données et est parfait pour l’hébergement de grandes quantités de données telles que la distribution audio, le stockage de photos à grande échelle, les données textuelles, les ensembles de données volumineuses, etc. Il est également idéal pour une utilisation multi-utilisateurs, permettant à des millions d’utilisateurs d’accéder aux fichiers stockés dans S3.
S3 peut également évoluer de zéro à des niveaux quasi illimités, ce qui en fait une ressource polyvalente pour les entreprises de toutes tailles.
L’un des meilleurs atouts de S3 est son prix abordable. Il s’agit d’un service de grande valeur pour le stockage et l’accès aux données, auquel on peut accéder par diverses méthodes, notamment l’interface graphique, l’interface de ligne de commande, les API AWS ou même des méthodes standards telles que HTTP. S3 est le service de stockage par défaut d’AWS, ce qui en fait un outil essentiel pour les entreprises qui dépendent d’AWS.
S3 fournit deux éléments de base :
– Les objets, qui sont les données stockées par S3, telles que les images, les fichiers, les vidéos, etc.
– Les compartiments, qui sont les conteneurs des objets, ce qui facilite l’organisation des données.
Les compartiments (ou Buckets)
Les compartiments S3 sont un élément essentiel d’AWS, et ils sont créés dans une région spécifique. Les données stockées dans un compartiment ont une région d’origine principale et y restent à moins que vous ou l’un de vos administrateurs système ne les configuriez de manière à ce qu’elles en sortent. Ceci garantit que S3 maintient une souveraineté de données stable et contrôlée. En créant un compartiment dans une région spécifique, vous pouvez contrôler les lois et réglementations qui s’appliquent à vos données. En outre, le rayon d’action d’une panne est limité à cette région, ce qui signifie que toute panne majeure, telle qu’une catastrophe naturelle ou une corruption de données, sera contenue dans cette région.
Chaque compartiment est identifié par son nom, qui doit être unique pour tous les comptes AWS et toutes les régions. Cela signifie que si vous choisissez un nom de compartiment, personne d’autre ne peut l’utiliser dans aucun compte AWS. Un compartiment peut contenir un nombre illimité d’objets, et comme la taille des objets peut varier de zéro à cinq téraoctets, un compartiment peut contenir une quantité infinie de données, ce qui en fait un système de stockage évolutif à l’infini.
En tant que système de stockage d’objets, les compartiments S3 ont une structure plate, ce qui signifie que tous les objets stockés dans le compartiment sont au même niveau. Contrairement à un système de fichiers, où les fichiers peuvent se trouver à l’intérieur de dossiers, tout est stocké dans le compartiment au niveau de la racine. Toutefois, lorsque vous dressez la liste d’un compartiment S3 sur l’interface graphique AWS, vous verrez ce qui semble être des dossiers, et l’interface utilisateur les présente comme tels.
Dans votre compte AWS, vous pouvez avoir jusqu’à 100 compartiments, qui est une limite souple. Cette limite peut être augmentée à l’aide de tickets d’assistance à AWS. Il est important de noter que le nombre de compartiments ne peut pas dépasser 1000, qui est une limite stricte.
Les objets
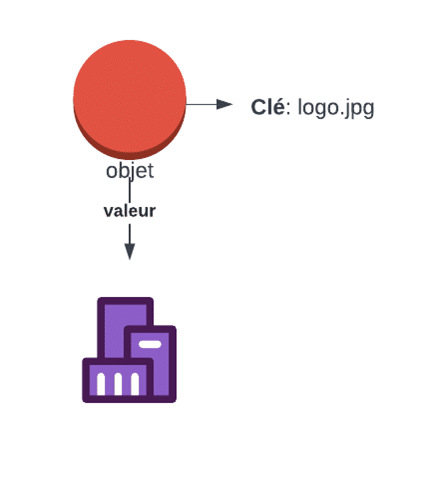
Lorsque l’on travaille avec S3, il peut être utile de considérer un objet comme un fichier. Bien qu’il y ait quelques différences conceptuelles, ils peuvent être interchangeables. Un objet S3 est composé de deux éléments principaux:
– **la clé**: vous pouvez l’assimiler à un nom de fichier. La clé identifie l’objet dans un compartiment. Ainsi, si vous connaissez la clé de l’objet et le compartiment, vous pouvez accéder à l’objet de manière unique (en supposant que vous ayez les autorisations nécessaires). Par défaut, même pour les services publics, il n’y a pas d’accès dans AWS initialement, sauf pour le compte de l’utilisateur root.
– **la valeur**: il s’agit des données ou du contenu de l’objet. Dans le cas présent, il s’agit d’une séquence de données binaires représentant un logo. La taille d’un objet peut aller de zéro octet à cinq téraoctets. Cela signifie que vous pouvez avoir un objet vide ou un objet d’une taille énorme de 5 TB. Cette évolutivité est l’une des raisons pour lesquelles S3 est si utile dans un grand nombre de situations.
Outre la clé et la valeur, il existe d’autres composants d’un objet, notamment l’identifiant de version, les métadonnées, le contrôle d’accès, etc. En comprenant ces composants, vous pouvez mieux utiliser S3 pour répondre à vos besoins.
Gestion des versions
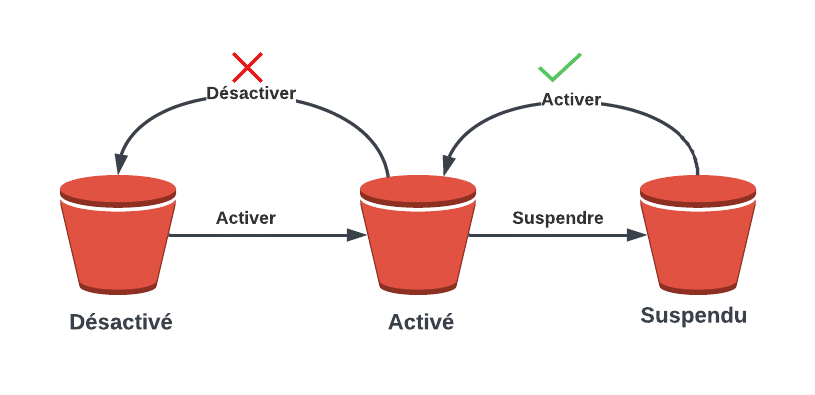
Le versionnage des objets est une fonctionnalité qui vous permet de stocker plusieurs versions d’un objet dans un compartiment. Par défaut, le versionnage est désactivé dans un compartiment, mais vous pouvez facilement l’activer si vous le souhaitez. Une fois activé, vous ne pouvez plus le désactiver, mais vous pouvez le suspendre si nécessaire. Une fois suspendu, il peut être réactivé à tout moment.
Si le versionnage n’est pas activé, chaque objet d’un conteneur est identifié uniquement par son nom unique, ou clé d’objet. Si vous modifiez un objet, la version originale est remplacée. Cependant, lorsque le versionnage est activé, toute modification d’un objet génère une nouvelle version tout en laissant l’original intact. Par exemple, disons que vous avez un compartiment avec une image appelée “logo.jpg”. Si vous modifiez ou supprimez cet objet, ces changements auront un impact sur l’objet original.
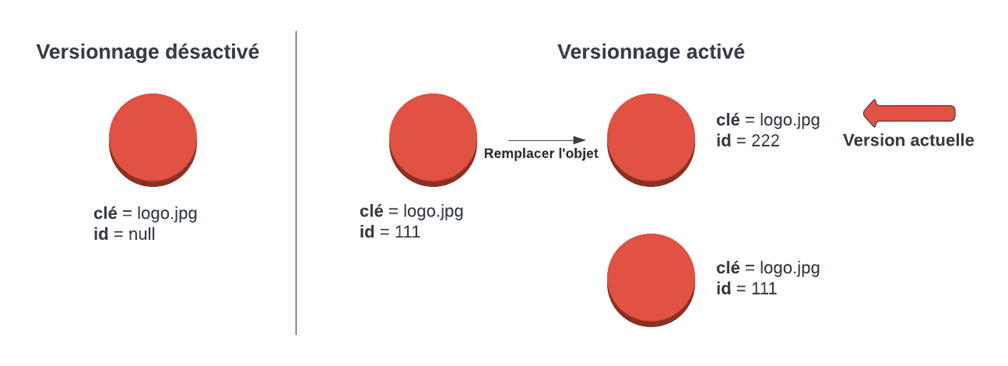
Chaque objet d’un compartiment à version possède un identifiant unique attribué par S3. Lorsque le versionnage est désactivé, l’ID des objets dans ce bac est défini comme nul. Cela signifie que toute modification apportée à un objet remplacera la version originale.
D’autre part, si vous téléchargez un nouvel objet dans un compartiment compatible avec les versions, S3 attribue un nouvel identifiant à cet objet. Toute modification apportée à cet objet génère une nouvelle version tout en conservant l’ancienne. La version la plus récente d’un objet se trouvant dans un compartiment à version activée est appelée la version actuelle de l’objet.
Lorsque vous accédez à un objet dans S3, si vous n’indiquez pas explicitement la version dont vous avez besoin, la version la plus récente sera toujours renvoyée. Cependant, vous avez la possibilité de demander une version spécifique en fournissant son identifiant. Cela signifie que les versions peuvent être accédées individuellement en spécifiant l’ID, et si aucun ID n’est spécifié, il est supposé que vous souhaitez interagir avec la version actuelle de l’objet.
Le versionnage affecte également les suppressions. Par exemple, si vous avez deux versions différentes de “logo.jpg” stockées dans un compartiment à versions et que vous indiquez à S3 que vous souhaitez supprimer l’objet sans spécifier d’identifiant de version, S3 ajoutera une nouvelle version spéciale de cet objet, connue sous le nom de “marqueur de suppression”. Ce marqueur de suppression n’est qu’une nouvelle version de l’objet qui donne l’impression qu’il a été supprimé, alors qu’en réalité, il est juste caché. Le marqueur de suppression est une version spéciale d’un objet qui cache toutes les versions précédentes de cet objet. Cependant, vous pouvez supprimer le marqueur de suppression, ce qui a pour effet d’annuler la suppression de l’objet et de ramener l’objet actuel à l’état actif. Toutes les versions antérieures de l’objet existent toujours et sont accessibles à l’aide de leur identifiant de version unique.
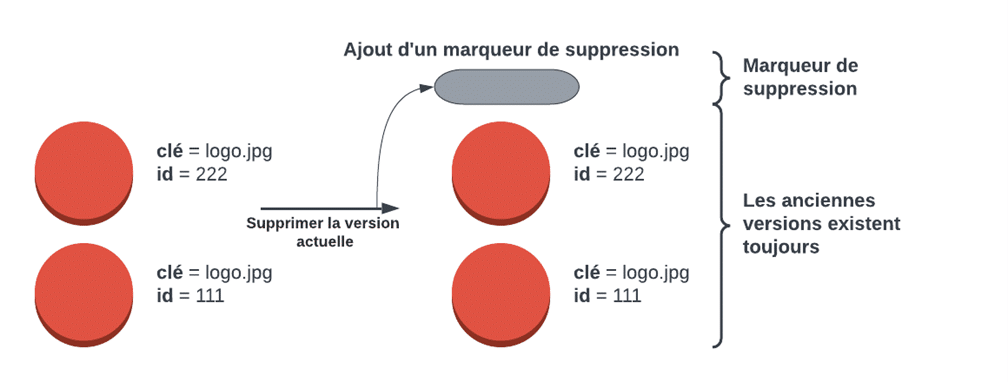
Même si le versionnage est activé, vous pouvez supprimer entièrement une version d’un objet en spécifiant l’identifiant de la version que vous souhaitez supprimer. Si vous supprimez la version la plus récente d’un objet, la version la plus récente suivante devient la version actuelle. Cela signifie que vous avez un contrôle total sur les versions de vos objets dans S3, ce qui vous permet de les gérer en fonction de vos besoins.
Il est important de comprendre que l’activation du versionnage dans un compartiment signifie que toutes les versions d’un objet resteront dans ce compartiment, ce qui entraîne une consommation d’espace pour chaque version. Par exemple, si vous avez un objet unique d’une taille de 1 Go et que vous avez dix versions de cet objet, vous consommez dix fois plus d’espace pour cet objet et ses multiples versions. En outre, vous serez facturé pour toutes les versions de tous les objets contenus dans un compartiment S3.
Pour optimiser l’utilisation du stockage et réduire les coûts, il est recommandé d’examiner et de supprimer régulièrement les versions inutiles des objets. Cette opération peut être effectuée manuellement ou à l’aide de politiques de cycle de vie. En mettant en œuvre ces bonnes pratiques, vous pouvez gérer efficacement votre stockage S3 et garantir une utilisation efficiente des ressources.
Classes de stockage
S3 propose plusieurs classes de stockage conçues pour répondre à différents cas d’utilisation, besoins de performance et exigences en matière de coûts. Chaque classe de stockage est optimisée pour des charges de travail spécifiques et s’accompagne de caractéristiques uniques en termes de durabilité, de disponibilité et de prix. Voici un aperçu des classes de stockage AWS S3 :
- S3 Standard : Cette classe de stockage polyvalente est idéale pour les données fréquemment consultées et les charges de travail Big Data, les sauvegardes et la distribution de contenu. Elle offre une faible latence, un débit élevé et une durabilité de 99,999999999 % (11 neuf).
- S3 Intelligent-Tiering : Conçue pour les données dont les schémas d’accès sont inconnus ou changeants, cette classe de stockage déplace automatiquement les objets entre deux niveaux d’accès (fréquent et peu fréquent) en fonction des schémas d’utilisation. Elle offre la même durabilité que S3 Standard et permet d’optimiser les coûts pour les données dont la fréquence d’accès varie.
- S3 Standard-Infrequent Access : S3 Standard-Infrequent Access est une classe de stockage à faible coût conçue pour les données auxquelles on accède moins souvent mais qui nécessitent un accès rapide en cas de besoin. Elle offre la même durabilité et la même disponibilité que la classe S3 Standard, mais à un coût inférieur. Avec S3 Standard-Infrequent Access, vous payez des frais de récupération lorsque vous accédez à vos données. S3 Standard-Infrequent Access est idéal pour les cas d’utilisation qui nécessitent un accès peu fréquent aux données, tels que les sauvegardes, la reprise après sinistre et le stockage à long terme.
- S3 One Zone-Infrequent Access (One Zone-IA) : Cette classe de stockage stocke les données dans une seule zone de disponibilité, ce qui la rend moins résiliente que les autres options, mais plus économique. Elle convient aux données rarement consultées qui peuvent être recréées en cas de perte, telles que les sauvegardes secondaires ou les données temporaires.
- Amazon S3 Glacier Instant Retrieval : Amazon S3 Glacier Instant Retrieval est une classe de stockage conçue pour le stockage à long terme de données auxquelles on accède rarement et qui doivent être récupérées rapidement. Cette option offre la solution la plus rentable, vous permettant d’économiser jusqu’à 68 % sur les frais de stockage par rapport à la classe de stockage S3 Standard-Infrequent Access (S3 Standard-IA), en particulier lorsque vos données ne sont consultées qu’une fois par trimestre.
La particularité de S3 Glacier Instant Retrieval réside dans sa capacité à fournir l’accès le plus rapide aux données archivées. Il offre le même niveau de débit et d’accès à la milliseconde que les classes de stockage S3 Standard et S3 Standard-IA. Il s’agit donc d’un excellent choix pour le stockage de données d’archives nécessitant un accès immédiat, telles que les images médicales, les médias d’information ou les archives de contenu généré par les utilisateurs.
Le téléchargement d’objets directement vers S3 Glacier Instant Retrieval est une option simple. Vous pouvez également utiliser les politiques de cycle de vie S3 pour transférer de manière transparente des données provenant d’autres classes de stockage S3. - Amazon S3 Glacier Flexible Retrieval (Auparavant S3 Glacier): S3 Glacier Flexible Retrieval offre une solution de stockage rentable, avec des coûts jusqu’à 10 % inférieurs à ceux de S3 Glacier Instant Retrieval. Cette option de stockage est conçue pour les données d’archives qui ne sont consultées que 1 à 2 fois par an et qui peuvent être récupérées de manière asynchrone.
Pour les données d’archives qui ne nécessitent pas un accès immédiat, mais qui ont besoin de flexibilité pour récupérer de grandes quantités de données sans coût supplémentaire, comme dans les scénarios de sauvegarde ou de reprise après sinistre, S3 Glacier Flexible Retrieval est la classe de stockage idéale. Elle offre un large éventail d’options de récupération qui permettent d’équilibrer les coûts et les temps d’accès, allant de quelques minutes à quelques heures, et propose même des récupérations en masse gratuites.
Cette solution de stockage est particulièrement adaptée aux besoins de sauvegarde, de reprise après sinistre et de stockage de données hors site. Elle est également idéale pour les situations où certaines données doivent occasionnellement être récupérées en quelques minutes, sans craindre d’encourir des coûts élevés.
S3 Glacier Flexible Retrieval est conçu pour assurer une durabilité maximale des données, avec une garantie de 99,999999999% (11 9s). En outre, il affiche une disponibilité impressionnante de 99,99 % en stockant les données de manière redondante dans plusieurs zones de disponibilité AWS physiquement séparées tout au long de l’année. - S3 Glacier Deep Archive : S3 Glacier Deep Archive est la classe de stockage la plus économique proposée par Amazon S3. Elle répond aux besoins de conservation à long terme et de préservation numérique des données qui ne sont consultées qu’une ou deux fois par an. Cette classe de stockage est spécialement conçue pour les clients opérant dans des secteurs hautement réglementés, tels que les services financiers, les soins de santé et les secteurs publics. Ces secteurs doivent souvent conserver des ensembles de données pendant de longues périodes, généralement de 7 à 10 ans, pour se conformer aux exigences réglementaires.
En plus de répondre aux besoins de conformité, S3 Glacier Deep Archive peut également servir de solution fiable pour les scénarios de sauvegarde et de reprise après sinistre. Il s’agit d’une alternative rentable et facile à gérer aux systèmes de bandes magnétiques traditionnels, qu’il s’agisse de bibliothèques sur site ou de services hors site.
Il fonctionne en tandem avec Amazon S3 Glacier, qui est mieux adapté aux archives où les données sont fréquemment récupérées et où certaines informations peuvent être requises en quelques minutes. Cependant, lorsqu’il s’agit de stockage à long terme avec des exigences d’accès minimales, S3 Glacier Deep Archive prend la tête.
Pour garantir une protection optimale des données, tous les objets stockés dans S3 Glacier Deep Archive sont répliqués et stockés dans au moins trois zones de disponibilité géographiquement dispersées. Cette redondance garantit un taux de durabilité remarquable de 99,999999999%. De plus, en cas de perte de données ou de suppression accidentelle, la restauration peut être effectuée dans un délai maximum de 12 heures.
Il est important de noter que chaque classe de stockage a sa propre structure tarifaire, certaines classes étant plus rentables que d’autres en fonction de vos besoins spécifiques. Par exemple, S3 One Zone-Infrequent Access est moins cher que S3 Standard, mais n’est peut-être pas la meilleure option pour les données hautement critiques en raison de sa résilience plus faible. De même, si S3 Glacier offre un stockage peu coûteux, l’extraction de données à partir de cette classe peut prendre plus de temps que les autres classes de stockage.
Dans un prochain article, nous explorerons les subtilités de chaque classe de stockage S3 et leurs cas d’utilisation respectifs. Cela permettra de mieux comprendre comment chaque classe peut être utilisée de manière optimale.
Article rédigé par Abdelbaki BEN ELHAJ SLIMENE, Senior Software Engineer.